The rapid development of large language models (LLMs) has revolutionized how businesses utilize artificial intelligence. Among the various techniques available for customizing these models to perform specific tasks, fine-tuning and in-context learning (ICL) stand out as the most prevalent methodologies. A recent study conducted by Google DeepMind and Stanford University sheds new light on the efficacy of these methods, revealing significant insights into their generalization capabilities which are critical for developers aiming to leverage LLMs for tailored enterprise solutions.
Fine-tuning is a conventional method involving additional training of a pre-trained LLM on a smaller, specialized dataset. This adjustment equips the model with new knowledge or skills, enhancing its performance in specific contexts. Conversely, ICL presents a unique approach by keeping the model’s parameters intact; instead, it leverages contextual examples within the input prompt to address new queries. This distinction is pivotal as it points toward varied computational costs and application efficiency associated with each method.
The Research Breakthrough: A Methodological Comparison
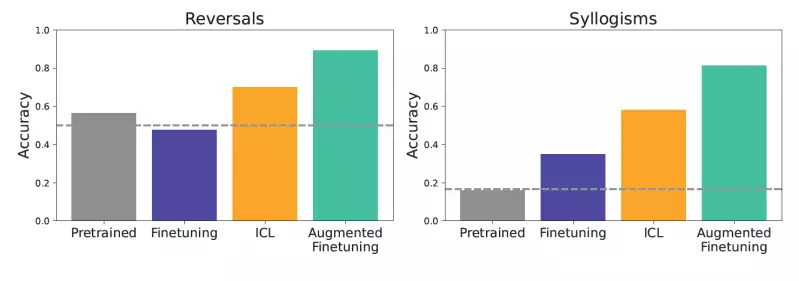
The study endeavored to rigorously evaluate how well these two learning paradigms support generalization across unfamiliar tasks. By employing “controlled synthetic datasets” with intricate, imaginary structures, such as fictional family trees, the researchers ensured that the experiments were purely focused on the models’ abilities to generate novel knowledge without any pre-existing bias. The testing involved several cognitive challenges—reversals and syllogisms, proving the models’ deductive reasoning skills under constraints designed to test their adaptability and comprehension.
For instance, the model’s ability to reverse statements—like deducing that “glon are less dangerous than femp” if it knows “femp are more dangerous than glon”—was examined alongside simpler logical deductions. The control over variables and the use of nonsensical terms served as rigorous measures of model generalization, emphasizing the extent to which LLMs could extrapolate from available data without resorting to memorization.
Shifting the Paradigm: The Augmented Fine-Tuning Approach
Remarkably, the findings of this research highlighted that while ICL boasts superior generalization in matching data contexts, it comes at a higher computational price due to its reliance on extensive prompts. In response to these challenges, the researchers proposed a groundbreaking synthesis of the two methods: augmented fine-tuning. This innovative approach enhances fine-tuning processes by integrating in-context learning examples into the training dataset.
The augmentation strategies explored by the researchers focus on generating rich, informative examples that not only improve fine-tuning efficacy but also significantly enhance generalization capabilities. The dual strategies—a local one optimizing individual data pieces and a global one leveraging entire datasets for generating contextual inferences—tripled the output’s richness. This not only boosted the model’s proficiency but also raised the bar for potential applications across various enterprise functions.
Real-World Implications for Enterprises
For developers, the implications of augmented fine-tuning are profound. By investing in the creation of ICL-augmented datasets, enterprises can achieve a dual advantage: enhanced model generalization while managing long-term computational costs effectively. For example, a model fine-tuned with insights derived from enhanced in-context inferences can seamlessly field a diverse range of queries related to proprietary data while minimizing extensive inferences traditionally associated with ICL.
While the researchers acknowledged that this approach may escalate initial investment due to the additional steps involved in data augmentation, they also emphasized the cost-effectiveness of amortizing these expenses over numerous model applications. Essentially, as businesses increasingly seek to implement AI solutions, the enhanced generalization from augmented fine-tuning could mean the difference between a competitive edge and remaining stagnant in the marketplace.
A Call to Embrace Complexity in AI Learning
The study by Google DeepMind and Stanford University not only unveils the comparative strengths of fine-tuning and ICL but invites organizations to rethink their strategies in deploying language models. Optimizing LLMs for specialized tasks is not merely about choosing one technique over another; it’s about harnessing the strengths of both to forge a robust system capable of powerful predictive capabilities. The complexity of context and data interaction may define the next evolution of AI applications, opening doors to more nuanced and intelligent machines.
Fostering an environment that encourages ongoing research and experimentation will be essential as developers navigate the practicalities of adapting foundational models. As organizations strive to evolve in an era heavily influenced by AI, the choice of learning paradigms will shape the landscape of their digital futures. Ignoring these advancements could leave enterprises lagging behind in the race toward intelligent automation and smart decision-making.